Most rules engines need to support the concept of a list. Whether it
is a list of household members, a list of incomes, or a list of
expenses. Each list item also has multiple inputs (like "age" and "has
disability" for members). Imagine the following rule that we need to add.
The household doesn't need to meet the "resource test" if they have
anyone who is "elderly or disabled".
To model this you need 2 new facts. You could do this as one, but for
the sake of simplicity I did not want to come up with a scenario where
you would need to split this into 2 parts. You need a fact that checks
if each member is "elderly or disabled", and you need a fact that uses
the new "is elderly or disabled" fact and checks if any of them are true.
When implementing this in DMN it would look something like this.
// Decision: elderlyOrDisabledMembers
for member in members
return member.isElderly or member.isDisabled
// Decision: meetsResourceTest
(some result in elderlyOrDisabledMembers satisfies result)
or resourcesWithinLimit
It is already getting hard to read, and it gets even more difficult
when you need to use "is elderly or disabled member" alongside other
member level fields, for example if you needed to use it alongside
hours worked for work requirements. The best solution would be to
split all of the member level calculations into their own DMN graph,
and pass the results to the household level graph.
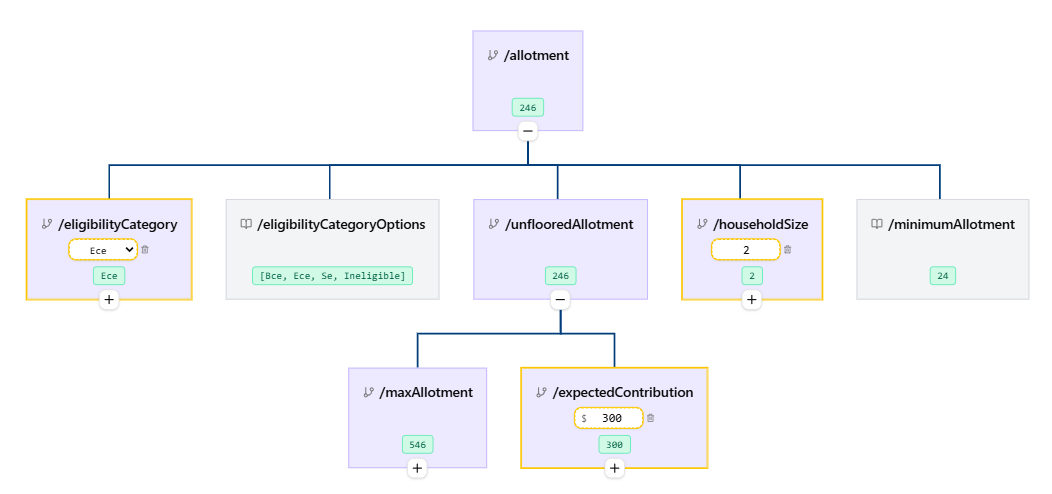
Fact Graph solves this in a better way. It allows the user to define
additional member level derived fields. In the example above that
would look like:
<Any>
<Dependency path="../isElderly" />
<Dependency path="../isPersonWithDisability" />
</Any>
The ../factName path syntax lets you access other facts,
both writable and derived, for that particular member. That means that
you can then use the "is elderly or disabled fact" in a member level
meets work requirement by simply referencing it with
<Dependency path="../isElderlyOrDisabled" />. Then when
you need to aggregate all of the members at a household level you can
do that using one of the aggregation tags (admittedly more verbose than
the DMN version).
<GreaterThan>
<Left>
<Count>
<Dependency path="/members/*/isElderlyOrPersonWithDisability" />
</Count>
</Left>
<Right><Int>0</Int></Right>
</GreaterThan>
Another feature of collections that Fact Graph has that I found out
about while researching for this blog that I wish I knew about while
building our SNAP implementation, is called aliases. During my
implementation of SNAP, I had to use the following pattern in multiple
places.
<CollectionSum>
<Switch>
<Case>
<When><Dependency path="/members/*/isPartOfHousehold" /></When>
<Then><Dependency path="/members/*/grossIncome" /></Then>
</Case>
<Case>
<When><True /></When>
<Then><Dollar>0</Dollar></Then>
</Case>
</Switch>
</CollectionSum>
An alias is just a filtered subset of another collection. For example,
you could make an alias for household members that is all of the
members that meet the criteria for "is part of household". With an
alias that would turn the above code into this.
<CollectionSum>
<Dependency path="/householdMembers/*/grossIncome" />
</CollectionSum>